Papercut
Well, I was on my way to Japan this morning (I guess it was technically yesterday morning), and I had recently cut my finger putting away some dishes into a picnic basket. While waiting in line, I asked a man behind me in line for his pen, and realized when I was using his pen that my finger was bleeding all over the page that I was trying to fill in. I don’t think that he noticed, but I am sure that he wouldn’t have been too happy about a stranger bleeding all over his pen. No big deal; what he doesn’t know can’t hurt him. Besides, I’m pretty sure that the blood donor clinic would have let me know if I had some serious disease (I visited them last month and haven’t been into any risky activity since then).
Anyhow, I continue onto customs and fill out the redundant custom form. Again, noting that my finger is kind of bleeding, but at least thinking that it was contained. As I got up to the customs guard, I dropped some blood on his counter and quickly tried to wipe it off. I looked down and noticed that there was some on the form that I had just finished completing. “Are you bleeding he says”, looking over to the counter where I left a droplet. I confirmed, and he half-assed put on some gloves, cleaned up the counter, and said that it was hazardous or something. I was thinking that I was going to miss my flight because my finger is barely bleeding–the cut is almost as minor as a paper cut. But he just escorted me to some other guards that gave me a band-aid and some hand sanitizer.
He was pretty nice about it, but I am sure that it ruined his day. If the tables were turned, and if I were at a certain paranoid phase in my life, I would probably have anticipated the worst (maybe even years later). Anyhow, if you are reading this, I am sorry. There were no band-aids at our house, and this was not top priority at 3:30AM when gathering my shit to go overseas.
Actually, come to think of it. For how often I have had open wounds, in some dirty places (e.g., skate spots covered in pigeon shit), I am surprised that I am not more concerned about thinks like this.
OpenOffice3
Wow! OpenOffice3 rules. But it reaches its true potential only when gstreamer is used as the backend for video. I am sure that I have run into this problem before: make a presentation on one platform (some fedora core). and then go to transfer to another computer and decide to upgrade OpenOfffice. I would typically do this using the binaries from OpenOffice, and then fiddle around with settings wondering why my ffmpeg encoded videos no longer work. The problem is that the binary packages on OpenOffice’s site are not packaged with the gstreamer back-end. For sure the version in fedora’s repositories use gstreamer.
In order to get this working last night, I decided to just upgrade to FC11 on my laptop. This was rather painless, and most of my own code compiled without problems. It seems that they are still cleaning up the standard include files, so I just had to add some missing “#include
Japan tomorrow. And I am friggin’ tired.
OOoLatex
I’m always on the fence about what to use for creating presentations. Whenever there are formulas (and you have already written a paper) it is nice to use the pdf/latex tools for presentations. But then again, laying out the images and embedding movies in these presentations nearly outweighs any benefits.
On the other hand, it is nice to have the layout (& movie) features of OpenOffice, but it would have been nice if OpenOffice used latex natively for its formula editor. Enter OOolatex, the latex editor extension for OpenOffice. This is a duo that is hard to beat.
(non)-rigid tracking
In the past little while I have been trying to determine a way that dense geometric deformations can be reconstructed and tracked over time from a vision system. The main application is to track dense geometry deformations of a human subject over time so that they can be played back under novel view and animation conditions.
It is assumed there are only a few cameras (with known pose calibration) observing the scene, so it is desirable to take advantage of as much temporal information as possible during the reconstruction. As a simpler starting point for this problem, I felt it appropriate to work on the reconstruction of dense geometry for a moving human head.
Many existing tracking methods start with some known dense geometry, or assume that the geometry can be reconstructed at each time instant. In our case, neither of these assumptions hold, the latter because we have only a few cameras. The general problem is therefore to reconstruct a dense model, and its deformations over time.
A part of the problem is to reconstruct the motion of the rigid parts. This can be done using all available cues, e.g., texture and stereo. And it too can be accomplished with different representations (e.g., a set of points, a mesh, or level-sets). In these notes, I considered this problem alone: given an approximate surface representation for a non-rigid object, find the transformations of the surface over time that best agree with the input images. Keep in mind, however, that these ideas are motivated by the bigger problem, where we would like to refine the surface over time.
In this example, intensity color difference (SSD) tracking was used to track a skinned model observed from several camera views. The implementation is relatively slow (roughly 1 frame a second), but I have also implemented a GPU version that is almost 7 fps (for 12000 points and two bones, one 6.dof base/shoulders and a 3 dof neck, with 4 cameras).
There is a pdf document with more details posted as well.
Some videos are given below.
An example input sequence. The video was captured from 4 synchronized and calibrated cameras positioned around my head.
If we just run a standard stereo algorithm, we will get some noisy results. Ideally we would like to track the head over time and integrate this sort of stereo information in the coordinate frame of the head. This part is hard as the surface is open.
Tracking the head alone would allow the registration of these stereo results in a common coordinate frame, where temporal coherency makes more sense. The video below demonstrates this idea, although I haven’t found a good solution for merging the stereo data.
| Tracked head | Depth registered in coordinate frame of head |
The following videos are more related to the tracking using a skinned mesh and an SSD score. In the following videos the tracked result on the above input sequence using a mesh generated from the first frame is illustrated below. The mesh has two bones: one 6 D.O.F for the shoulders and another for the 3 D.O.F. neck/head.
The tracking currently ignores visibility; this can cause problems when many of the points are not visible. An example of this mode of failure is given in the following sequence. This sequence was captured under similar conditions, although the left-right motion is more dramatic (more vertices are occluded). Additionally, this sequence has some non-rigid motion.
| Input sequence | noisy depth from stereo |
| Tracked head and shoulders. Notice the failure when the head is turned too far to the left. | |
These videos, and the original avi’s are available in the following two directories:
seq0-movies and seq1-movies. You will need vlc, or mplayer, ffmpeg, (maybe divx will work) to view the avi’s.
Code for Rodrigues’ derivatives: roddie. Included as I merged this code into my articulated body joint.
Tobogganing image effects
Not too long ago I was reading a bunch of segmentation papers and came across “tobogganing” for unsupervised hierarchical image segmentation/clustering. Tobogganing is similar to watersheds and starts by clustering pixels into neighboring pixels that have the lowest gradient magnitude. The technique is efficient and can be made hierarchical by introducing a measure of similarity between neighboring clusters (the similarity is based on average colors and variances). This gives rise to a hierarchy of segmentations.
The method was used in LiveWire-based segmentation techniques (i.e., intelligent scissors), and has also been used in its hierarchical form for interactive medical image segmentation. In the latter application, the
hierarchy allows for quick solutions by computing the solution on the coarsest levels, and only refining it to finer levels when necessary. Thus avoiding redundant computation far away from the segmentation boundary.
I was interested in this application of tobogganing, and had to refrain from trying to implement it as I had no real use for it. But I also thought that the method might be useful for creating interesting image effects, which would be useful in another side-project. So, with application in mind, I tried a quick implementation this past weekend.
I have several potential ways of using the segmentation, but one of them was to try and help identify image edges that were more salient than the ones you typically get out of an edge processing algorithm (maybe smoothing regions with some Laplacian regularizer would give neat looking shading).
Below are some illustrations of the hierarchy for some input images. Tobogganed regions have been replaced with their average color.

Tobogganing effects (bike image)

Les neil tobogganing segmentation
The rightmost image gives an idea of how image edges could be used; the image edges extracted from an edge operator have been modulated with those extracted from the coarse levels of the tobogganed regions. Click on image for full-resolution. They are pretty big.
Preliminary source code:
iPhone sqlite3 slow joins?
A friend and I have been working on a small iPhone app, and we have been using an sql database for our data store. There had been large lags in our system for loading/saving (which we have now made lazy), but the majority of this was due to encoding images as PNGs/JPEGs. The storing into BLOBs didn’t appear to be all that slow, so I am fairly confident that sqlite3 was not to blame.
However, in our initial UITableView a number of objects are loaded from the database, and contain thumbnails (64×64 ish), and some meta-data collected from a simple join on a couple tables. This join collected information from children objects (such as size of blobs), and number of children objects. Surprisingly, with only 8 objects in the database, this loading step sometimes took longer than 2 seconds (including DB setup time). This timing seemed to scale roughly linear with the number of objects in the DB.
| Num Objects | Using join | Cached stats |
| 3 | 0.95 | 0.53 |
| 5 | 1.12 | 0.65 |
| 7 | 1.33 | 0.81 |
| 8 | 1.44 | 0.84 |
So each entry adds roughly 0.11s, and initialization takes roughly 0.4-0.5s. We get a slight improvement with caching the sizes (again I find this odd, as there are so few entries in the DB). Taking out the processing for the thumbnails (decoding), the times for 3 entries drop from 0.95 to 0.55 and 0.53 to 0.16 (for cached). So loading 4 thumbnails takes roughly 0.4/3s, approx 0.13s. This still seems pretty slow, but the difference in 0.55 and 0.16 seems to suggest that the originial query is that much slower.
I still think that this loading should be faster, but we may have to look into other ways to load the header info if there are many entries.
Long time, no bloody post.
Sometime, about two weeks ago, I decided to give blood for the first time. This is one of those things that I have wanted to do for a long time, but for some reason never got around to making an appointment.
After making the appointment, I was anticipating the donation. I figure I am a pretty healthy guy, and went in to my appointment about an hour after eating a hearty meal of veggie nuggets and heaps of pasta. I haven’t been drinking coffee lately, but I figured I drank as much water as I normally would (which really isn’t all that much). After being hooked up to the passive blood-sucking machine, I enjoyed watching my body’s red-oil drain out. After all, it is for a good cause; unlike fossil fuels, it is renewable.
The donation tech had mentioned to let her know if I started to feel strange. Sure enough, somewhere halfway in, I started to feel strange. I waited just long enough so that I could barely express this feeling to the tech, and within seconds they had me propped up in the seat with moist towelettes on my forehead. I was within seconds of passing out; the transfusion was stopped. I had never felt this before, and remained in a state of half awareness while contemplating what had just happened. Slightly embarrassed that I wasn’t able to donate blood properly. Naturally, I started to question if there was something that I could have done differently.
I could have drank more water. And maybe it didn’t help that the day before, I had done my first brick workout with my girlfriend, who was training for a triathlon (the workout was a 20km bike followed by a 5km run). I haven’t run in a long time, and maybe I didn’t hydrate properly after. Whatever the case, the nurse assured me not to feel negatively about my experience. I didn’t. She also questioned me on what I ate, and gave some tips for next time (like coming in after 3 squares). But I was already thinking about the next time. Unlike many other things, I am determined to complete this. Until it is ruled out that I cannot donate blood (the nurse mentioned some people just can’t), I will fault myself for my own failure. I consider my experience a positive one, as I was able to feel something I hadn’t felt before, and I learned something about myself. I encourage you to donate blood as well.
Later in the day, I went to visit my parents. I just wanted to just relax. The TV was on in the kitchen, tuned in to the Simpsons. Ironically, it was an episode where Homer donated blood (although Google doesn’t seem to be giving me any hits for this episode). I found this amusing.
In a little over a month I will be able to donate again.
Off-line, reading, dreading the coming spring.
Haven’t got much done lately. Was working on revising an old paper for resubmission, which required rereading all the literature. It is mostly on interactive segmentation, so I got a chance to read some other image segmentation papers that I haven’t read before (e.g., the math behind intelligent scissors or livewire). Some cool methods based on shortest paths, dynamic programming, random walkers, weighted distances, and level sets. And of course the graph-cut techniques. I particularly like the methods that do region clustering on the image data (e.g., Live Surface or Lazy snapping), which then allows for either a faster (possibly hierarchical) segmentation. Such clustering seems to be appearing other areas of vision, such as stereo and flow computations (there is a new cvpr09 paper for flow). I am holding myself back from implementing one of these because I don’t need it for anything.
There are lots of nice details for automatic matting (e.g., Bayesian matting and the extensions in GrabCut). The matting tries to determine the foreground and background colors as well as the compositing factor, typically given a trimap (bg/fg labels and the portion in between where the matting happens). In the past I have just used a trilateral filter (using color, distance, and alpha) to get a better border, but these methods would work far better.
Aside from reading, I have also been trying to clean up my multicapture dc1394 code. It is by no means clean yet, but it is better than it was. More details to come in the project page: http://www.neilbirkbeck.com/?p=1359
The cleaning up involved learning more of the boost library, which I am ashamed that I haven’t exploited earlier. On the other hand, most of what I was changing was to remove dependencies on Qt for lower parts in the architecture. I still prefer Qt’s QFile, QFileInfo, QDir to boost::filesystem, but boost::filesystem is pretty handy. Same goes for boost::format and boost:regex.
MCap
Capture from multiple libdc1394 /firewire cameras on different hosts. Each host can have several cameras. The library bases the multi-host communication on the pvm library. Higher level classes are used to develop the UI (Qt)
Mode of operation assumes that recorded files will be sent back and used in post processing. Files can be encoded on the client side (using mencoder) and then transferred back, or saved in a raw binary form for transfer after. Alternatively, for short sequences, or when the disk or encoding is a bottleneck, the client side saves images in memory buffers and transfers them after the recording is complete. Raw files from multiples hosts are merged and can be viewed with a simple multi-video viewer. File transfer is done with a combination of scp/ssh and TCP/IP sockets; as such it will probably take some effort to port to windows.
MCap supports changing features and settings, or loading configurations of cameras from files (in a crude manner).

Issues: changing video modes sometimes causes failures (possibly due to trying to allocate more bandwidth than the1394 bus can handle). Failure is painful due to
Planned (Maybe): add ability to plugin framesinks (for transfer, encoding), or other filters and processing so the client can do processing in real-time applications.
To come: possibly a system architecture, source code, and some videos.
Semi-global MMX
Yesterday I came across the paper “Accurate and Efficient Stereo Processing by Semi-Global Matching and Mutual Information”. I have read this paper before, but yesterday I got the urge to write some code and decided to implement it. The semi-global (SG) matching technique is similar to the dynamic programming approaches for stereo-vision, except that it integrates costs across multiple paths (e.g., horizontal, vertical, and some diagonals), 16 of these in total. Instead of doing the typical DP backward pass where the solution is extracted, SG uses the sum of these costs through a pixel as the score and selects the best disparity label for each pixel.
Anyhow, the implementation is straightforward (with a sum-of-absolute difference matching score, at least). In the paper it is reported that the optimization takes roughly 1 second for some standard benchmarks, which is pretty fast for what is going on. My initial implementation was on the order of dozens of seconds for similar sequences.
The author suggests the use of SIMD, and definitely seems to have taken care in his implementation. Enter MMX. I haven’t written any MMX code for a while, but with compiler intrinsics I know that it is not as hard as the first time I did it (using inline assembly). I decided to take a crack at optimizing my implementation.
My first thoughtless implementation was to do several pixels in parallel. This quickly turned out to be problematic, as the multiple scan traversals would make it impossible to do this efficiently (at least I think so). The other solution is to parallelize the innermost loop that along a scan that for each disparity at a pixel must find the minimum over all the previous pixels cost plus some penalty that is dependent on the distance between the disparities.
/** \brief MMX-based per-pixel accumulation of scores. */ static void mmx_inner(const cost_type_t * score_base, cost_type_t * obase, cost_type_t * lcost, cost_type_t * lcost_prev, cost_type_t mcost_many[4], int ndisp, const cost_type_t p1[4], const cost_type_t p2[4]){ __m64 this_mins; __m64 mn = *((__m64 *)mcost_many); cost_type_t * next = lcost; for(int d0=0; d0<ndisp; d0+=4){ __m64 penalty = *((__m64*)(p1)); __m64 n = *((__m64*)(lcost_prev + d0)); //Only consider middle shifts (Are these correct?) n = _m_pminsw(n, _m_pshufw(n, 0x90) + penalty); n = _m_pminsw(n, _m_pshufw(n, 0xF9) + penalty); //Need two more operations for boundaries... if(d0){ __m64 t = *((__m64*)(lcost_prev + d0 - 1)); n = _m_pminsw(n, _m_pshufw(t, 0xE7) + penalty); } if(d0+1<ndisp){ __m64 t = *((__m64*)(lcost_prev + d0 + 1)); n = _m_pminsw(n, _m_pshufw(n, 0x24) + penalty); } penalty = *((__m64*)(p2)); //Now do all the disparities for(int d=0; d<ndisp; d+=4){ __m64 m5 = *((__m64*)(lcost_prev + d)); __m64 m6 = _m_pminsw(m5, _m_pshufw(m5, 0x93)); m6 = _m_pminsw(m6, _m_pshufw(m5, 0x4E)); m6 = _m_pminsw(m6, _m_pshufw(m5, 0x39)); n = _m_pminsw(n, m6 + penalty); } __m64 cost_many = *((__m64*)(score_base + d0)); __m64 c = cost_many + n - mn; *((__m64 *)(lcost + d0)) = c; *((__m64 *)(obase + d0)) += c;//*((__m64 *)(out + ndisp*x + d0)) + c; if(d0==0) this_mins = c; else this_mins = _m_pminsw(this_mins, c); } this_mins = _m_pminsw(this_mins, _m_pshufw(this_mins, 0x93)); this_mins = _m_pminsw(this_mins, _m_pshufw(this_mins, 0x4E)); this_mins = _m_pminsw(this_mins, _m_pshufw(this_mins, 0x39)); *((__m64 *)(mcost_many)) = this_mins; }
Now isn’t that pretty? Here’s the kicker. On the system I was developing this on (AMD Phenom II), I get a speedup (rather slowdown) of 0.43 (where MMX takes 2.29s, and basic takes 0.997s, for pass through a 1024×1024 image with 32 disparities).
But, on the machine that I had originally developed and tested (older compiler, Intel Quad Core), I get a speedup of roughly 10x, where the MMX takes 0.944s, whereas the basic takes 7.8s). This was the machine that I wrote the original basic implementation and decided it was slow enough to warrant hand optimization.
I am convinced that gcc’s internal vectorization has been improved significantly. Running the gcc 4.3.2 executable on the Intel machine, I get a little bit of a speedup: 1.2 (MMX takes 0.95s and Basic takes 1.12s).
Lesson: writing MMX code is fun (in that you feel like you accomplished something), but the last couple times I tried the compiler has done a better job (and it is much faster at it too!).
For the tsukuba data set, my code takes about 1.4s for 32 disparity levels. Without doing forward backward comparison, it gives pretty decent results too:

It is still slower than what is reported in the paper (and the paper is doing forward and backward comparisons). Now add some threading, we can get this down to about 0.59s (4 threads on quad core, where some other user is eating up some of one CPU). That is a bit better. We can get this down to about 0.38s (where 0.1s is the non-parallel matching cost computation and image loading). That is somewhat better; not real-time, but not worth any more effort to optimize.
I’ve uploaded the current source for this if you care to check it out. I don’t guarantee correctness or cleanliness: sgstereo. I was originally looking (albeit quickly) for semi-global matching source code and it wasn’t online in the first few hits. Now it is definitely online.
Next time I will have to remember to try compiling on a newer compiler before wasting any time with intrinsics. I think this has happened before…
CVPR
Just reviewing the CVPR 2009 papers, and wanted to make a few notes on papers that might be useful at sometime:
- Color Estimation from a Single Surface Color (Kawakami, Ikeuchi).
- Video Object Segmentation by Hypergraph Cut (Huang et al.)
- Photometric Stereo and Weather Estimation Using Internet Images (Shin and Tan); challenges are multiple viewpoints, different cameras.
- Real-Time Learning of Accurate Patch Rectification (Hintestoisser et al.); Learn a bunch of patches for an image template (based on warped versions of it, e.g., homography, computed quickly using a basis). In real-time can identify patch and coarse pose of patch (using these templates), which can then be refined (inverse compositional tracking). Can handle 10’s of reference features along with 70+ identified features in a frame in real-time).
- High Dynamic Range Image Reconstruction from Hand-held Cameras (Lu et al.); HDR from hand-held (not tripod) images, dealing with blur and misalignment.
- Contextual Flow (Wu and Fan)
Some other related papers that I came across as a result:
- Intrinsic Image Decomposition with Non-Local Texture Cues (Shen et al.); Decompose images into shading and albedo (with no other known information); group normalized pixels into regions that have similar texture in small neighborhood; find group reflectance s.t. it minimize cost function that keeps shading spatially smooth. Results look good.
- A projective framework for radiomatric image analysis (Tan and Zickler); projective framework and it’s use in autocalibration, etc.
- Isotropy, Reciprocity and the Generalized bas-Relief Ambiguity (Tan et al.); auto-calibration of photometric stereo.
- Reanimating Faces in Images and Video (Blanz et al.); this lead me to SPHYNX, which they used for converting text/speech into phonemes/visemes. Looked a little into this, but would take some time.
New site transferred
Well, after debating the directory structure for far too long, I decided to finally transfer the main site over.
You can still access the old site here, at least for a while.
I still have a bunch of things to finish up.
- The publications are still in the old database (although, they don’t change all that much and probably could be a static page).
- The latest movies and random movies in the sidebar widget are little plugins that I created (they need to be cleaned up; there probably are similar plugins to these)
- The media page just spits out all the media (should be paged and cleaner)
- The projects page somewhat resembles the old page, but I would like it to be more grid-based and less blog like
- Videos have always probably been somewhat incompatible (I always use ffmpeg, mencoder, or gstreamer) with standard OS installations. Need to automatically create derivatives of these. Youtube video’s need to properly reference thumbnails.
- Local meta-mirror needs to be modified, reorganized to reflect merges.
- Short tags or some other way to show/add thumbnails for my videos. Currently my videos use the old system for accessing thumbnails (subdirectory thumbs). Should be made to be more wordpress-like with postsmeta.
It’s a pretty long list, and I’m sure it will take me a while to get to it, but at least most of the things are up now.
Content Layout
I can’t seem to find a good solution to keep all of the old links (directory
structure) while maintaining full featured attachments in wordpress.
WordPress attachments seem to like to be in a subdirectory of the wordpress
root. Unfortunately, it would be nice to have the root in a subdirectory
of the web root (for clealiness), so I don’t want the two roots to coincide
(would end up more cluttered than it already is, with a bunch of wp files).
What would be ideal is the ability to put just the uploads in the root
directory and have wp somewhere else (but again, this wasn’t working entirely,
after several attempts).
I thought that the attachments would work fine if they were using absolute
paths, but this only partially worked. Some of the url grabbing for the
attachments was not using the GUID (which may be a deprecated feature), and
were instead just replacing the upload directory from the file uri to
get the web url. This obviously wasn’t working properly. The solution is
to then instead copy over most of the content to wordpress’s content directory.
This allows me to have some control over the directory structure (with
the add_from_server plugin, which allows adding media files from the
web serverr, which again only really worked with content nested in the uploads
directory). To maintain a fully workable previous version of the site, without
having two full copies of the content, I decided to keep as much old content
in the web root and move over everything from the old site into wordpresses
content directory. The old-site will then be fully operational from the WP
content directory (without rewriting any links). If it is ever desired to move
the old php stuff into a subdir, links will have to be reprocessed.
Stuff in the main directory that is probably going to stay:
- iphoneads
- yum
Stuff that should be mirrored (maybe, at least until the few people that have bookmarks have updated them):
- jshape (with warnings in root).
- images
- movies
- source
- glacier
Everything will be moved/deleted. There shouldn’t be many dead links, but there may be a couple.
Color Tracker
This last friday: I was reading a paper that integrated time of flight sensors with stereo cameras for real-time human tracking and I came across some old papers for color skin tracking. I couldn’t help myself from trying out an implementation of the tracker: color_tracker and color_tracker2
It is really simple, but works pretty good for fast motions.
Another reference was on boosting for detection of faces in images. I was tempted to try and implement a version. It’s a good thing it was closer to the end of a Friday, so I didn’t start…which is probably a good thing as I have little use for such a beast.
Vids will probably only play if you have VLC or Divx installed (encoded with ffmpeg and the usual incompatibility problems)
![]()
![]()
Prelim version
Posted by in News on July 2nd, 2009
Oh yeah, the test version of the new site is currently here
Swiss ranger videos
Posted by in News on July 2nd, 2009
Added some videos to the swiss ranger that use texture from image sequences. I had been working with calibrating the cameras relative to the scanner and felt I needed to show something about it.
Also trying to transfer this site over to a wordpress. Most of the scripts are ready to pull stuff out of my DB. Already spent far too long working on it, but it may not be done for a few days yet.
Glaicer flow and more wigglers
Posted by in News on June 21st, 2009
Test of optic flow on glaciers
More wigglers (they aren’t the greatest):
jay ollie,
jay kickflip,
adam noseslide,
Some blender models
Posted by in News on May 31st, 2009
I found some old models of humans computed from shape-from-silhouette that might be useful to someone. I put them up here for the time being “ models , but I will probably add them to the database as assets.
Wiggles
Posted by in News on May 4th, 2009
The wiggler. And others A Sunday morning well spent. Inspiration: Mr. Unibrows.
{kind=link}
Segmentation tool
Posted by in News on April 23rd, 2009
This is a project that I have been working on for quite some time now. Not too long ago I tried out an idea with a shape prior. I had wanted to post the details for some time, but finally there is at least something up. See the project page.
Segmentation Tool
Posted by in Projects on April 22nd, 2009
Overview
The segmentation tool started as a simple 3D segmentation
viewer with crude interaction to inspect the results of
an automatic level-set variational segmentation. Since then
several semi-automatic intelligent tools have been incorported
into the viewer. These tools take the region statistics from a
user selection and try to intellgently dileneate the boundary
of the users selection; these allow a user to roughly specify the
region of interest (be it some anatomical part, or a tumor),
while the software takes care of extracting the boundary.
The tool is currently in a beta stage, but has been used in our
lab to perform segmentations for several research projects. Possibly,
in the future, it will be open-sourced.
Features
- Multiple segmentation layers
- Semi-automatic interactive tools (graph-cut based)
- Different region statistics modes (histograms, independent histograms, mean)
- Slice-locking fixes segmentation on a slice; also ensure 3D automatic tools do not interfere with user segmentations
- Plugin-based interaction tools
- 3D-view, multiple 2D views (with different image modalities).
- Dicom loading (using gdcm library)
- Cross-platform (Linux/Windows, probably Mac)
Screenshots
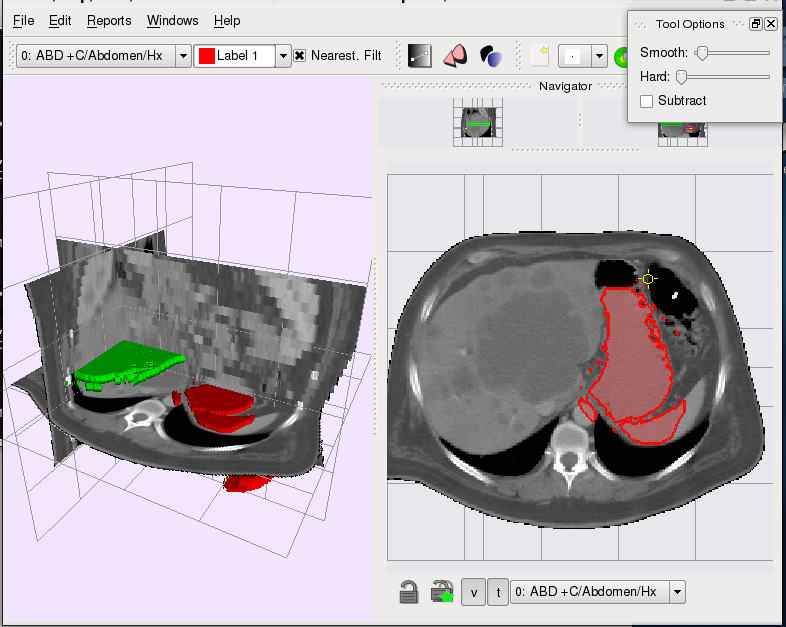
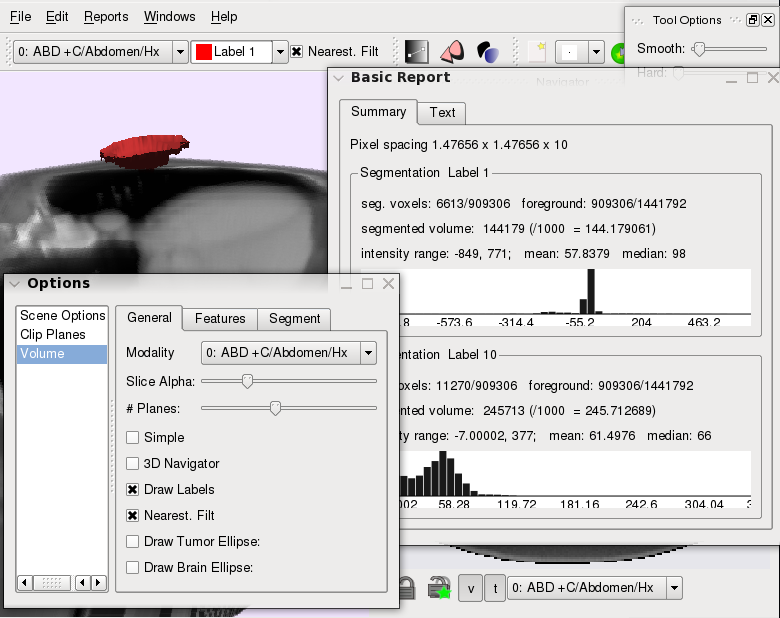
Contributors
Neil Birkbeck, Howard Chung, Dana Cobzas.
Proving Ground
The tool also serves as a proving ground for other semi-automatic segmentations. In an attempt to improve
the segmentation when a prior shape was known (for example, a mean shape from previous segmentations), an extension was developed to perform an optimization over shape deformation (rigid transformations + non-rigid transformations) while keeping the resulting segmentation close to the mean shape. Below are some of the videos related to the implementation of this idea (a short presentation, with no references, is also available: levprior.pdf).
The video links illustrate a selection (which mimicks the mean shape), followed by the optimization of the segmentation (hardness_mid.mp4/ hardness_mid.flv, varying_hardness.mp4/ varying_hardness.flv). The hardness parameter determines how close the segmentation is to the mean shape. The interp video ( interp.mp4/ interp.flv) shows how a single mean shape can carry over to different slices. Ideally this would be done in 3D with a fixed 3D mean shape. Finally, with this model it is easy to introduce more user constraints in the form of point constraints (point_cons.mp4/point_cons.flv).
Recent upgrade
Posted by in News on April 17th, 2009
I recently upgraded to a Phenom II X4. Didn’t want to upgrade OS (FC9), but as the new HW didn’t work directly with my previous installation, I really had no choice.
Upgrade was rather painless. Some problems with some of my packages due to upgrades to sip (e.g., __setitem__ no longer takes multiple arguments).
Only other problems were the typical Flash installation pain, sound not working out of the box (M4A78 Pro Mobo), and temperature sensors not working. The first two are solved (alsa-drivers package solved sound), but I still don’t have a solution for the sensors. I did, however, try out FC11 beta earlier, and the sensors seemed to work then. Tried recent version of lm_sensors with no luck either. Guess I’ll have to wait.
Most of the settings are complete, so I can, hopefully, resume to normal work.
Passive walker
Posted by in News on March 28th, 2009
Added some details about what I played around with for half of this week (an implementation of a passive walker). There is a lot more to be said about it, but you will have to read Brubaker’s paper (or his thesis) to get the details.
I also added some animations that will be useful for the wxshow.
Passive Walker
Posted by in Projects on March 28th, 2009
In the past week (late March 2009), I kept coming across the same paper (by Brubaker et al.) that used an anthropometric passive walker for a prior in people tracking. I had read the paper in the past, but this time I couldn’t contain the urge to implement some of the ideas. This is the result of that impulse.
The passive walker contains a spring in between the hips and has a parameter for the impulse recieved on collision. From these two parameters you can generate different styles of walking; you end up with the ability to generate cyclic gaits for different speeds and stride lengths. The walker only has two straight legs, but Brubaker suggests a method to map this to a kinematic structure. The screenshot below shows several walkers attached to a kinematic structure and skinned mesh.anim

It is better illustrated in the movie, in which I am controlling the speed/step size of the gait by the mouse movements:
The movies (passive.mp4, passive.flv)
I spent about an hour throwing together something that tried to pose the rest of a mesh using the walk cycle. The idea was to use a training set of poses (from motion capture data), and pick poses for the upper body from the training sequence based on the orientation fo the lower joints. I’m sure it could be done better. Below are some examples: the left hand side shows some poor resutlts (due to overconstrained joint angles); the right side shows unposed upper body. Some of these sequences are avaibale to use (anims) with the viewer on the wxshow page.

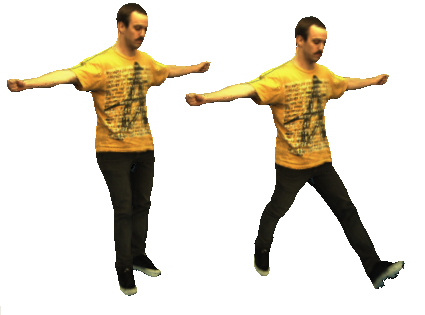
A document containing some of my implementation details:passive.pdf
wxshow
Posted by in News on March 9th, 2009
The last weekend I worked on a cross-platform utility for viewing the models of my research. Not quite done yet, but updates will appear on the new project page.
-
You are currently browsing the archives.
Latest Movies



Random Movies